Ob bei der Qualitätskontrolle, der Steuerung von selbst fahrenden Autos oder Drohnen oder der automatischen Auswertung von Bildern und Videos, das Maschinensehen spielt in der Entwicklung künstlicher Intelligenzen eine wichtige Rolle. Was uns Menschen leicht fällt und selbstverständlich vorkommt, muss jeder künstlichen Intelligenz in mühevoller Kleinarbeit beigebracht werden. Hierfür stehen verschiedene Methoden der Bildannotation zur Verfügung, die alle ihre eigenen Vorteile und Nachteile besitzen und für die beabsichtigte Anwendung korrekt ausgewählt werden müssen.
Inhalt
- Bildannotation in der Praxis – wie die Maschinen das Sehen lernen
- Bildannotation und ihre Typen – von Bounding Boxes bis Cubes
- Auswahl der Annotationsmethode – das richtige Werkzeug
- Fazit
1. Bildannotation in der Praxis – wie die Maschinen das Sehen lernen
Auf dem Bildschirm erscheint eine typische Straßenszene, wie sie sich in Deutschland tausende Male abspielt. Vor der Motorhaube eines Autos kreuzen einige Fußgänger an einer roten Ampel die Straße. Hinter den Fußgängern fahren einige Autos und Busse über die Querstraße. Was für das menschliche Gehirn leicht zu verarbeiten ist, muss jedoch für eine künstliche Intelligenz in verständliche, auswertbare Signale übersetzt werden. Der vor dem Bildschirm sitzende Benutzer beginnt, um verschiedene Objekte im Bild bunte Kästen zu ziehen: grüne Rahmen um die Fußgänger, blaue um die Ampeln, rote um alle Fahrzeuge. Für das Fahrverhalten irrelevante Dinge werden ignoriert. Sind alle relevanten Dinge markiert, kann das Bild zum Training einer künstlichen Intelligenz genutzt werden. Aber was sind die Hintergründe dieses Annotationsverfahrens und welche anderen Möglichkeiten bieten sich?
2. Bildannotation und ihre Typen – von Bounding Boxes bis Cubes
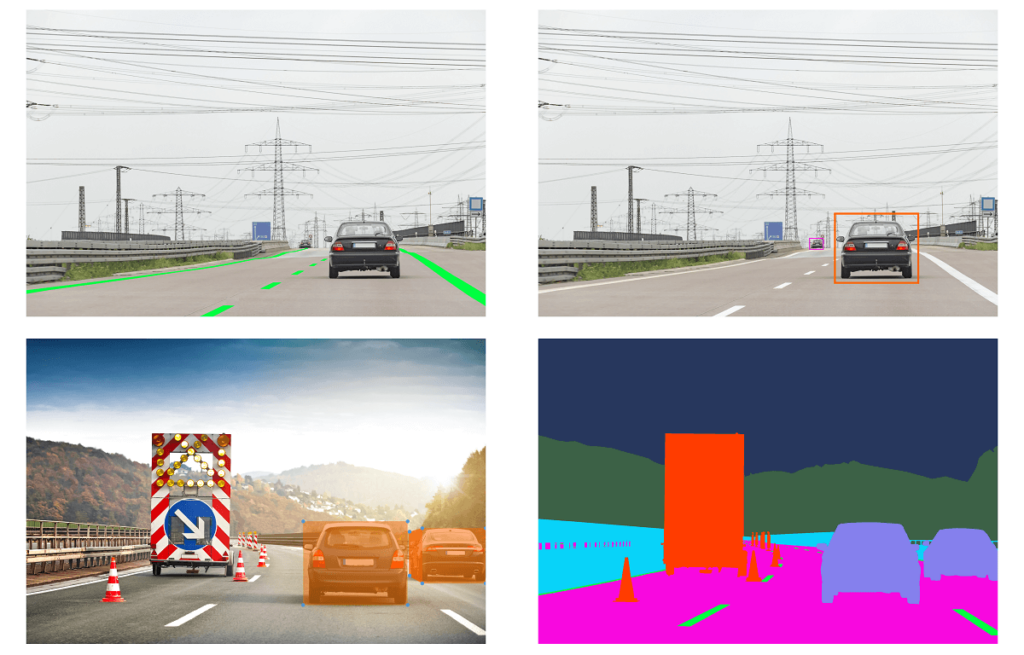
Für die Annotation von Bildern stehen verschiedene Werkzeuge zur Verfügung, welche die auf dem Bild abgebildeten Informationen verarbeiten und für die künstliche Intelligenz verständlich machen. Die einfachste Methode ist die der „Road Lines“, bei der auf der Straße abgebildete Fahrlinien ausgewertet werden. Diese sind statisch, klar kontrastiert und vermitteln eindeutige Informationen für das Fahrverhalten. Wenn es darum geht, nicht nur zweidimensionale Straßenlinien, sondern Objekte zu annotieren, sind „Bounding Boxes“ das Mittel der Wahl. Hier werden, wie im oben genannten Fallbeispiel, Rahmen um verschiedene Objekte gezogen, die dann von der künstlichen Intelligenz wiedererkannt werden. Ähnlich verhält es sich mit den sogenannten „Cubes“. Hier sind die Rahmen dreidimensional und bilden die Objekte im Raum ab. Die höchste Genauigkeit erhält man dann, wenn bei der „Full Segmentation“ alle Objekte auf dem Bildschirm pixelgenau farbig markiert und so annotiert werden.
3. Auswahl der Annotationsmethode – das richtige Werkzeug
Bei den Verfahren der Bildannotation geht es immer darum, die in der Wirklichkeit vorhandenen Informationen zu abstrahieren und auf ihre für die künstliche Intelligenz relevanten Informationen zu reduzieren. Je mehr Objekte die künstliche Intelligenz erkennen kann, desto genauer werden ihre Berechnungen. Allerdings erhöht jede zusätzliche Information auch den Rechenaufwand und führt nicht unbedingt zu einer Verbesserung des Verhaltens. Außerdem gestaltet sich eine genauere Annotation zeitaufwendiger und ist damit kostspieliger als eine simplere Methode. Für die automatische Auswertung von Videomaterial, etwa für die automatische Gesichtserkennung, genügen meistens zweidimensionale Rahmen, die um Gesichter und relevante Gesichtsmerkmale gezogen werden, damit die künstliche Intelligenz sie mit einer Datenbank abgleichen kann. Wenn es darum geht, ein Fahrzeug im Straßenverkehr zu lenken, ist eine Kombination dieser Methode mit Road Lines häufig die beste Wahl, denn damit können alle relevanten Informationen schnell und einfach dargestellt und für die künstliche Intelligenz zur Verfügung gestellt werden. Deutlich aufwendiger ist die Bildannotation mit Cubes, denn hier werden die Objekte nicht nur zweidimensional, sondern dreidimensional annotiert. Eine solche Annotation lohnt sich vor allem für selbst gelenkte, schnell fahrende Autos oder Drohnen. Am zeitaufwendigsten, aber auch am genauesten ist die Full Segmentation. Hier werden alle Objekte des gesamten Bildes pixelgenau annotiert und können zum Training der künstlichen Intelligenz ausgewertet werden.
4. Fazit
Die korrekte Auswahl der Bildannotationsmethode ist ein wichtiger Schritt in der Entwicklung künstlicher Intelligenzen. Nur unterstützt durch das menschliche Auge können Maschinen trainieren, ihre Umwelt wahrzunehmen und mit dieser korrekt zu interagieren. Dieser zeitaufwendige, aber einfache Prozess kann nicht automatisiert werden und bedarf deshalb zahlreicher Arbeitsstunden. Hier können Crowdsourcinganbieter wie wir von Crowd Guru wertvolle Unterstützung bei der Entwicklung der Technologie von Morgen leisten.