Künstliche Intelligenzen (KI), die hinzulernen, klangen noch vor wenigen Jahrzehnten nach Science-Fiction; Mittlerweile lösen sie aber schon immer komplexere Aufgaben. So steht etwa das autonome Fahren kurz vor seinem Durchbruch und Google leitet aus wenigen Suchbegriffen unsere eigentliche Suchintention ab. Auch Machine Learning (maschinelles Lernen) als Teilgebiet von KI ist eine Schlüsseltechnologie für die Zukunft, denn die meisten KIs bauen inzwischen auf Machine Learning Lernen auf.
Die Grundlage des Machine Learning ist ein riesiger Erfahrungsschatz, der es einem System ermöglicht, möglichst viele Situationen zu meistern, die im Einsatz auf sie warten – sowohl vorhersehbare als auch unvorhersehbare. Daher sind die Menge und Qualität der Trainingsdaten, mit der die KI gefüttert wird, von entscheidender Bedeutung. Was Sie bei der Auswahl und Klassifizierung der Datensätze beachten sollten, erfahren Sie in unserem folgenden Guide.
Wie sehen Trainingsdaten für Machine Learning aus?
Trainingsdaten für maschinelles Lernen beinhalten Beispiele, auf deren Basis die KI später eigenständig Muster und Zusammenhänge erkennen soll. Im ersten Schritt werden Datensätze erhoben und anschließend für die KI klassifiziert, um ihr die Einordnung der Daten zu ermöglichen.
In folgenden Bereichen kommt Machine Learning heutzutage zum Einsatz:
- Text-Datensätze – etwa für Programme zur inhaltlichen Analyse von Texten (Beispiel) und für Chatbots
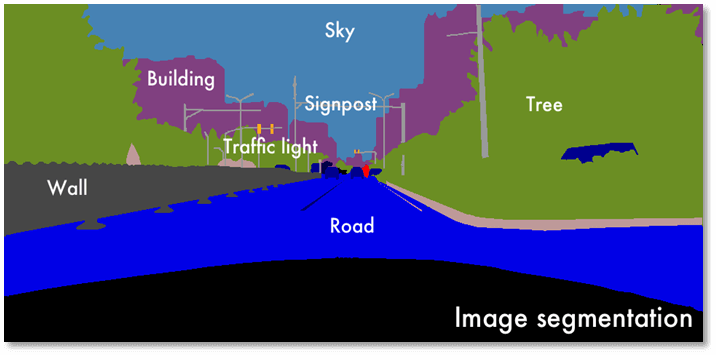
- Bild-Datensätze –für Programme zur Erkennung von handschriftlichen oder digitalen Texten oder zur Umgebungserkennung beim autonomen Fahren (Beispiel)
- Video-Datensätze – für Systeme, die mit der Erkennung von Bewegtbildern arbeiten, zum Beispiel zur Erkennung von unangemessenen Inhalten auf Streaming-Plattformen
- Audio-Datensätze – zum Beispiel für Systeme der Spracherkennung, unter anderem Sprachassistenten wie Amazon Alexa und Google Assistant
Je nach Aufgabe der KI kann die Komplexität der Datensätze unterschiedlich ausfallen, von einfachen Ja-/Nein-Abfragen bis hin zu mehreren Differenzierungsgraden – etwa Farben, Mimik/Gestik und Bewegungen.
Anhand eines Projekts für autonomes Fahren lässt sich beispielhaft verdeutlichen, worauf bei der Erstellung und Interpretation von Datensätzen für maschinelles Lernen geachtet werden muss:
- Wie „sieht“ die KI? Wertet sie im späteren Einsatz Fotos oder Videos (oder eine Kombination) aus, um die gelernten Muster anzuwenden? Aus welchen Perspektiven betrachtet das System den Straßenverkehr? Welche Auflösung haben die entsprechenden Kameras?
- Auf dieser Basis wird nun Material zu sämtlichen Situationen gesammelt, die auftreten können: unterschiedliche Sichtverhältnisse, unterschiedliche Umgebungen, Verhalten anderer Verkehrsteilnehmer usw.
- Dieser Datenpool wird nun manuell bearbeitet und klassifiziert: Manuelle Markierungen auf Fotos/Videos geben der KI Orientierung, um beispielsweise Farben und Formen zuordnen zu können: Was ist eine Ampel? Was ist ein Fußgänger? Wie können andere Fahrzeuge aussehen?
- Auf der Grundlage dieses Datenpools findet ein Abgleich mit weiteren Test- und Validierungsdaten statt, um eine sogenannte „Überanpassung“ an die Trainingsdaten zu verhindern.
Was sind Faktoren für hochwertige Trainingsdaten?
Das System wird dann zu einem Erfolg, wenn es aus den gelernten Inhalten auch in neuen Situationen die richtigen Schlüsse zieht. Um im Beispiel des autonomen Fahrens zu bleiben, können die Trainingsdaten selbstverständlich nicht auf jede Situation im Verkehr vorbereiten, außerdem nicht auf jedes einzelne Aussehen eines Fußgängers oder jedes zukünftige Automodell. Bei entsprechenden vielen und gut aufbereiteten Datensätzen reicht der Erfahrungsschatz der KI jedoch aus, um bisherige Muster auf Neues anzuwenden – so, wie wir Menschen auch in Sekundenbruchteilen aufgrund unseres Wissens eine neue Situation einschätzen können.
Die Datensätze für Machine Learning sollten daher auf folgende Punkte überprüft werden:
- Aus welcher Quelle stammen die Datensätze? Woher (aus geografischer Sicht) stammen die Daten und aus welchem Zeitraum? Es ist einleuchtend, dass sich mit Szenen aus dem englischen Straßenverkehr der 70er Jahre kein System zum autonomen Fahren trainieren lässt, das in Deutschland zum Einsatz kommt.
- Verschaffen die Datensätze der KI einen objektiven Überblick? Einseitige Trainingsdaten – zum Beispiel ausschließlich Fahrten bei strahlendem Sonnenschein – verfälschen die Muster, auf deren Basis die KI später entscheiden wird.
- Welche Informationen sind wichtig, um die KI zu trainieren? Welche Informationen hingegen sind überflüssig? Diejenigen Daten, die die KI nicht auf ihre spätere Aufgabe vorbereiten, sollten Sie bei der Klassifizierung gar nicht erst erfassen.
Um nicht auf vorhandene Datensätze angewiesen zu sein, die womöglich zu ganz anderen Zwecken angefertigt wurden, sollten Sie in Erwägung ziehen, die Trainingsdaten selbst in Auftrag zu geben. So haben Sie die volle Kontrolle über alle erfassten Daten und können den Qualitätsfaktor entscheidend beeinflussen.
Crowdworker mit der Erstellung hochwertiger Trainingsdaten beauftragen
Trainingsdaten selbst beauftragen – ist das nicht zu teuer und zeitaufwendig? Nicht, wenn Sie auf die Vorteile des Crowdsourcings zurückgreifen und Crowdworker einsetzen.
Folgende Arbeiten bieten sich an, von der Crowd übernommen zu werden:
- Sie haben kein ausreichendes oder fehlerhaftes Trainingsmaterial? Per Crowdsourcing lassen sich im Handumdrehen neues Datenmaterial nach Ihren Vorgaben erstellen.
- Sie benötigen Hilfe bei der Sichtung und Klassifizierung der bereits vorhandenen Trainingsdaten? Mittels Crowdsourcing werden Ihre Datensätze mit Tags und Markierungen versehen und im Anschluss genau kontrolliert.
- Sie wollen wissen, wie die KI arbeitet? Unzählige Crowdworker testen, wie sich das System nun verhält und wo eventuell nach Nachbesserungsbedarf besteht.
Damit sich die Crowdworker an die Arbeit machen können, geben Sie Folgendes vor:
- Aufgabenstellung: Welche Daten sollen erhoben werden?
- Auftragsvolumen: Wie viele Datensätze sind notwendig, um die KI ausreichend zu trainieren?
- Qualitätskriterien: Nach welchen Kriterien kann die Qualität eines Datensatzes sichergestellt werden?
- Format: Wie sollen Ihnen die fertigen Datensätze bereitgestellt werden?
Der Erfolg des maschinellen Lernens hängt entscheidend von der Auswahl der Datensätze ab. Investieren Sie Zeit und Energie bereits an dieser Stelle, um später auf langwierige und kostspielige Korrekturen verzichten zu können!